


What is a SQL database?
A guide to the structure and function of an RDBMS with SQL


Preface✨
In my previous article “An Introduction to SQL in Data Engineering”, I briefly touched on databases and the objects associated with them. This article aims to dive deeper into what they are, what they contain and how they benefit data engineering operations.
What is a database?🤔
A database is a collection of data that is structured in a certain way. The data itself can be anything recorded such as text, numbers, sounds, images, etc. The structure of the database depends on the database used such as relational, graph, document etc. For instance, a relational database organises data into rows and columns, but a document database stores data in JSON and XML documents.
For example, when you take a photo or record a video on your mobile device, the media file is stored on your phone’s memory or SD card, and the metadata of the file such as its name, type, size, timestamp, location etc is recorded on the database your phone’s gallery app is using. The gallery app uses the database to display, edit and share your photos and videos on your phone.
Database management system (DBMS)🌌
A database management system (DBMS) is software that allows users and applications to interact with the data in a database - think of them as APIs for databases. Databases are not limited to storing data - they are units for accessing and manipulating data too, and DBMSs play a pivotal role in making this possible.
Several files of different types are stored in the DBMS to easily find the data a user or application requests. DBMS software would include SQL Server, Redis, MongoDB, MySQL etc
Types of DBMS🌐
In general, there are 4 different types of DBMS:
Relational database management system (RDBMS)
NoSQL DBMS
Object Oriented DBMS
Hierarchical DBMS
Network DBMS
1. Relational Database Management System (RDBMS)📑
A relational database management system (RDBMS) stores data in a tabular format, or tables (rows and columns), which can be linked to each other based on similar attributes to create more enriched datasets.
These systems also adhere to ACID principles (Atomicity, Consistency, Isolation, Durability), ensuring the reliability and integrity of data when transactions are performing database operations behind the scenes.
Notable examples of this include SQL Server, PostgreSQL, Oracle, MySQL, among others.
Sidenote: Every RDBMS is a DBMS, but not every DBMS is an RDBMS. The same applies to the other systems mentioned after this.
2. NoSQL DBMS⛔️🔍
NoSQL stands for “Not only SQL”, which implies that this type of DBMS is not restricted to SQL’s conventional approach to storing data. The NoSQL approach permits data with any structure to be stored, and this includes document-based, key-value pairs, among others.
NoSQL, or “Not only SQL”, is a DBMS type that breaks away from SQL’s conventional approach. SQL stores tabular data, while NoSQL stores multiple data structures like document-based, graph-based, key-value-pairs, etc.
Examples of this include MongoDB and DynamoDB.
3. Object Oriented DBMS🧩
An object-oriented DBMS (OODBMS) works with complex data objects that mirror the ones used in object-oriented programming (OOP). In OOP, everything, from cars to phones, is an object. These objects encapsulate every behaviour and attribute you would find in the real world around you.
An OODBMS stores data as objects and forms relationships between them through
classes - the container of an object that describes its attributes and methods (or behaviours)
inheritance - the properties of an object adopted from another class
associations - an attribute that connects one class with another
Because OODBMS caters to large complex relationships between different data objects, it offers high performance and scalability to support geographical data, multimedia content, 3D modelling data, among others.
Examples of this include Objectivity/DB, Gemstone/S, ObjectDB etc.
4. Hierarchical DBMS🌳
The hierarchical DBMS organises data like a tree, where there is a single parent node, and multiple child nodes progressing from, therefore forming parent-child relationships across different records of data.
For a deeper dive into this, check out my previous article “An Introduction to SQL in Data Engineering” here.
5. Network DBMS🕸️
This DBMS type is an extension of its hierarchical counterpart mentioned previously. The only true distinct with this approach is that a child node can have multiple parent nodes.
More information on this can be found in my previous article “An Introduction to SQL in Data Engineering” here.
In this article, we’ll be delving into relational databases, so therefore the term database and relational database may be used interchangeably.
Anatomy of a database🦴
A database can be made up of the following:
Tables
Views
Schemas
Indexes
Stored procedures
Functions
Triggers
Demo🧪
To demonstrate how each of the data objects is used, we’ll be creating mock data on a list of favourite foods for random people. PostgreSQL will be used to illustrate the concepts but the ideas mentioned can be easily transferred into other SQL environments.
Tables💻
A table is a database object made up of data structured into rows and columns, where each row represents a record and each column represents a field of data.
Tables form the foundations of a relational database. Segregating data into specific tables enables easier data retrieval and quicker searches.
Example
We’ll create the following tables:
favourite_foodsfor representing favourite foods,favourite_drinksfor representing favourite drinks,favourite_snacksfor representing favourite snacks
Let’s start by creating the table for each person’s favourite food:
CREATE TABLE IF NOT EXISTS public.favourite_foods (
person_id SERIAL PRIMARY KEY,
person_name VARCHAR(30),
food VARCHAR(30)
);
INSERT INTO public.favourite_foods (person_name, food) VALUES
('Melissa', 'Pizza'),
('David', 'Burger'),
('Nathaniel', 'Pasta'),
('Samantha', 'Tacos'),
('Tom', 'Steak');
Now let’s create another for the favourite drinks:
CREATE TABLE IF NOT EXISTS public.favourite_drinks (
person_id SERIAL PRIMARY KEY,
person_name VARCHAR(30),
drink VARCHAR(30)
);
INSERT INTO public.favourite_drinks (person_name, drink) VALUES
('Melissa', 'Pineapple Juice'),
('David', 'Orange Juice'),
('Nathaniel', 'Lemonade'),
('Samantha', 'Water'),
('Tom', 'Coffee');
…and finally the favourite snacks:
CREATE TABLE IF NOT EXISTS public.favourite_snacks (
person_id SERIAL PRIMARY KEY,
person_name VARCHAR(30),
snack VARCHAR(30)
);
INSERT INTO public.favourite_snacks (person_name, snack) VALUES
('Melissa', 'Crisps'),
('David', 'Cookies'),
('Nathaniel', 'Popcorn'),
('Samantha', 'Sweets'),
('Tom', 'Peanuts');
If done, should look like this in Postgres:
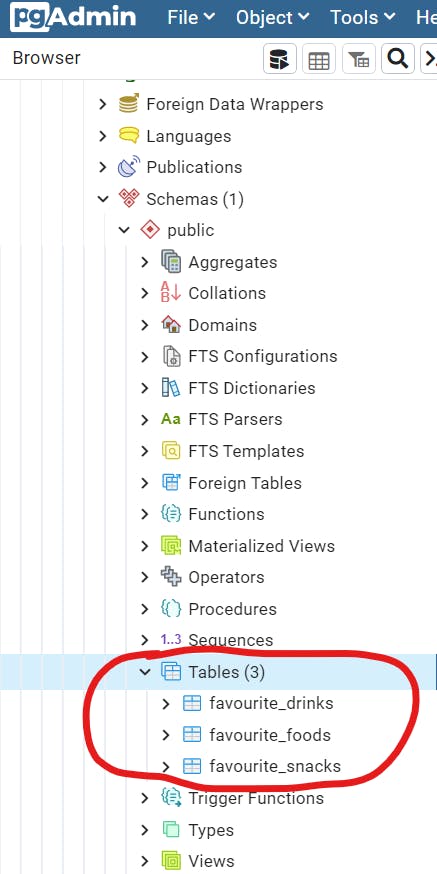
Now we can observe what we have in each table:
SELECT * FROM public.favourite_foods;
SELECT * FROM public.favourite_drinks;
SELECT * FROM public.favourite_snacks;
This is what is returned:
favourite_foods
| person_id | person_name | food |
| 1 | Melissa | Pizza |
| 2 | David | Burger |
| 3 | Nathaniel | Pasta |
| 4 | Samantha | Tacos |
| 5 | Tom | Steak |
favourite_drinks
| person_id | person_name | drink |
| 1 | Melissa | Pineapple Juice |
| 2 | David | Orange Juice |
| 3 | Nathaniel | Lemonade |
| 4 | Samantha | Water |
| 5 | Tom | Coffee |
favourite_snacks
| person_id | person_name | snack |
| 1 | Melissa | Crisps |
| 2 | David | Cookies |
| 3 | Nathaniel | Popcorn |
| 4 | Samantha | Sweets |
| 5 | Tom | Peanuts |
Views🖼️
A view is a special table that displays the results of a defined SQL query. Views don’t store data but show them in a structured format, which is why they’re often referred to as virtual tables - they behave like tables but do not persist in any data in the database.
The rows and columns a SQL view displays are derived from the underlying SQL tables powering it, and views can also be updated, inserted, or deleted, depending on the access permissions of the user managing the SQL view at the time or the underlying SQL script’s complexity.
With views, you can:
Simplify complex SQL queries
enforce business rules as SQL logic
protects sensitive data by controlling what can and cannot be shown from source tables
We'll explore another code example to demonstrate what views look like. Let’s combine each person’s favourite food, drink and snack:
SELECT
f.person_name,
f.food,
d.drink,
s.snack
FROM public.favourite_foods f
INNER JOIN public.favourite_drinks AS d
ON f.person_id=d.person_id
INNER JOIN public.favourite_snacks AS s
ON f.person_id=s.person_id
Instead of writing this out every single time, let’s create a view to simplify this:
CREATE VIEW combined_favourites AS
SELECT
f.person_name,
f.food,
d.drink,
s.snack
FROM public.favourite_foods f
INNER JOIN public.favourite_drinks AS d
ON f.person_id=d.person_id
INNER JOIN public.favourite_snacks AS s
ON f.person_id=s.person_id ;
…now I can talk to the view instead of rewriting the entire complex code again, and I can run this instead:
SELECT * FROM combined_favourites;
…which returns this:
| person_name | food | drink | snack |
| Melissa | Pizza | Pineapple Juice | Crisps |
| David | Burger | Orange Juice | Cookies |
| Nathaniel | Pasta | Lemonade | Popcorn |
| Samantha | Tacos | Water | Sweets |
| Tom | Steak | Coffee | Peanuts |
Schemas 🗂️
A schema is a database container that organises data objects into a structured collection. A schema is usually managed by a database owner who can grant or revoke permissions that allow access or modification of the objects within the schema. Some of the objects include tables, indexes, stored procedures, among others.
A schema can only belong to one database, but a database can have multiple schemas.
Example
If we wanted to create a new schema called food_preferences, we can do this:
CREATE SCHEMA IF NOT EXISTS food_preferences;
which should look like this:
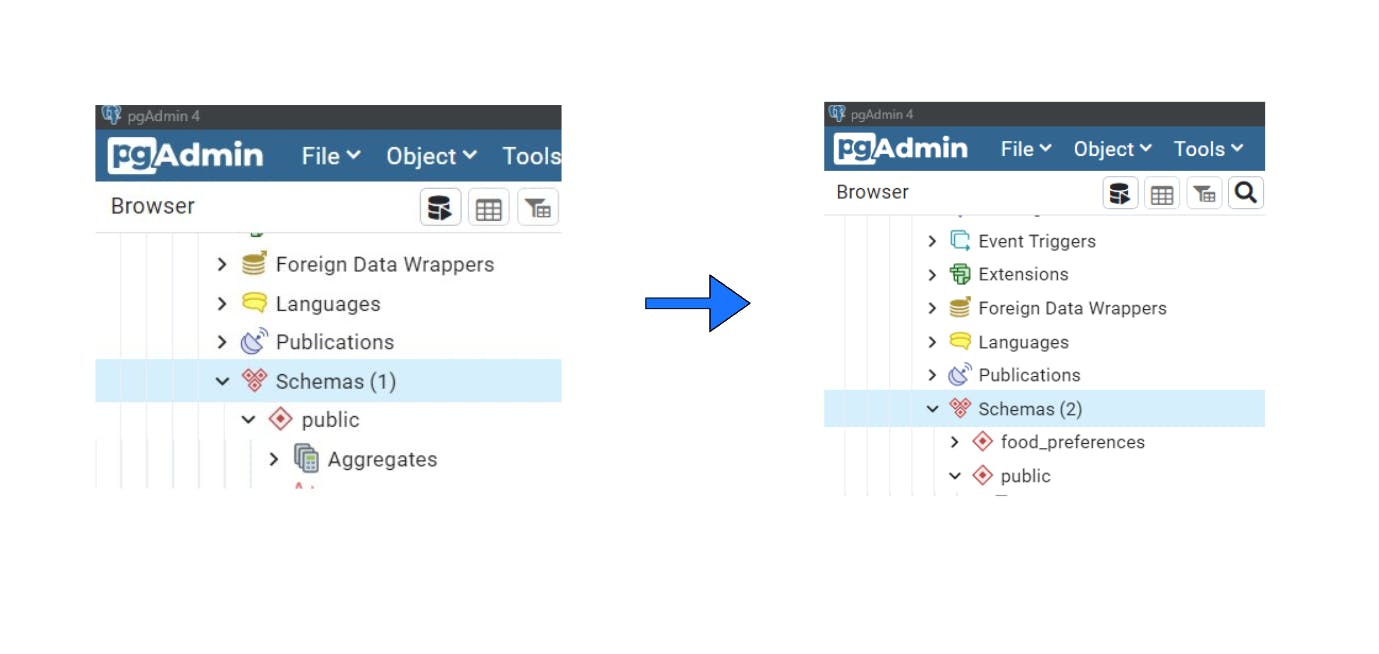
As you can see in the above image, we've now added the food_preferences schema successfully.
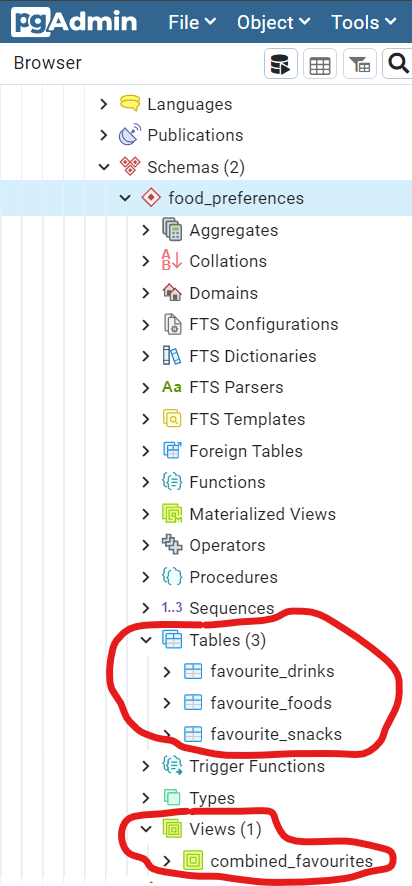
Now let’s migrate all our data from the public schema into the food_preference one. We’ll start by migrating the tables using the ALTER TABLE command:
ALTER TABLE public.favourite_foods SET SCHEMA food_preferences;
ALTER TABLE public.favourite_drinks SET SCHEMA food_preferences;
ALTER TABLE public.favourite_snacks SET SCHEMA food_preferences;
…then we do the same for the combined_favourites view:
ALTER VIEW public.combined_favourites SET SCHEMA food_preferences;
Indexes🚀
An index is a database object that enables the database system to retrieve data faster for users and applications.
Under the right conditions, an index can quickly locate rows that match the provided search condition without the need to scan the entire table. This is done by applying the index to one or more columns of a table or view so that the values of those columns are stored in that sorted order.
I find the easiest way to explain it is to describe what life without them can be like, perhaps through an analogy. Indexes are like signs in a supermarket that point you to different aisles that contain the items you need to purchase on your shopping list. Instead of scanning every aisle yourself or asking the staff for each item on your list, the signs can direct you themselves to save you from wasting time and energy. The signs are like indexes, and the items are like the rows and columns in a table.
When to use🚦
You should consider using indexes when you are frequently:
joining tables by the same column(s)
querying the same large tables with many rows
sorting and grouping data by the same column(s)
performing queries on a column with low cardinality (small number of distinct values)
When to avoid🚫
You should probably avoid using indexes if:
the column contains several NULLs
your table is small (small number of rows)
the table column has high cardinality (large number of distinct values)
Note: Each scenario would be different, so use this at your discretion
Example
Let’s imagine we query the food_preferences.count_favourite_foods table often based on the person_name and food columns (and let’s also imagine it’s a table with many rows because indexes are usually more practical for large tables).
If we want to speed up the queries used, we can create an index on these columns:
CREATE INDEX idx_favourite_food_name
ON food_preferences.favourite_foods(person_name, food);
Now if you want to find the index in Postgres, you can run this:
SELECT
indexname AS index_name,
indexdef AS index_definition
FROM
pg_indexes
WHERE
schemaname = 'food_preferences'
and indexname LIKE 'idx%';
…which should return something like this:
| Command Name | SQL Command |
| idx_favourite_food_name | CREATE INDEX idx_favourite_food_name ON food_preferences.favourite_foods USING btree (person_name, food) |
Stored procedures🛠️
A stored procedure is a group of SQL statements stored in a script that performs a specific unit of work. This includes selecting, modifying, inserting, updating, deleting data among other tasks.
Stored procedures can
accept input arguments
Be reused multiple times
Be executed by any authorized user or application
When to use🚦
You should consider using stored procedures when you:
are frequently running the same complex SQL operations
require a system to access data in a controlled manner
When to avoid🚫
If you are running simple CRUD operations (Create, Read, Update, Delete), stored procedures may be an overkill. Simply stick to executing the simple SQL scripts directly.
Example
Why write the entire SQL statement to fetch the favourite food of a particular person every single time when we can simply encapsulate the same SQL logic into a stored procedure and run it?
Let’s give it a go:
CREATE OR REPLACE PROCEDURE food_preferences.get_favourite_food(IN p_name VARCHAR(30), OUT fav_food VARCHAR(30))
LANGUAGE plpgsql
AS $$
BEGIN
SELECT food INTO fav_food FROM food_preferences.favourite_foods WHERE person_name = p_name;
END;
$$;
The stored procedure was successfully created if pgAdmin looks like this:
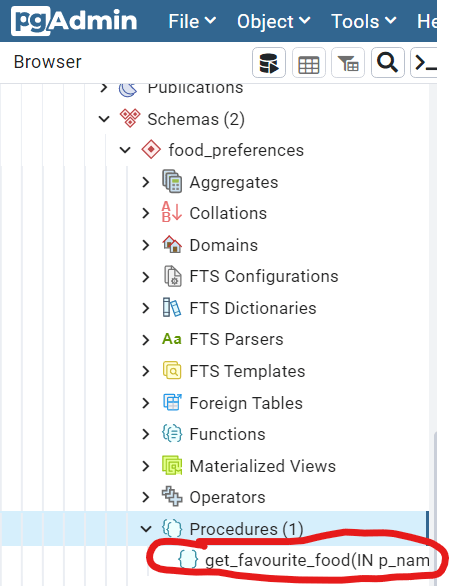
To call the procedure, we can use the following statement:
DO $$
DECLARE
result_food VARCHAR(30);
BEGIN
CALL food_preferences.get_favourite_food('Melissa', result_food);
RAISE NOTICE 'Melissa''s favourite food is %', result_food;
END $$;
…which should return this:
NOTICE: Melissa's favourite food is Pizza
DO
Functions📐
A function is a stored command used to return a single value (or scalar value) when you pass input parameters into it.
There are different types of functions:
In-built - functions already in the RDBMS
User-defined - custom functions created by users
In-built functions
Relational database management systems have functions already programmed into the system for developers to use straight away for data analysis and transformation purposes. Examples of some of these in-built functions include:
Window functions
Aggregate functions
Date functions
String functions
User-defined functions
These are functions that a user develops and saves on the RDBMS system. They can be reused like in-built functions once they’re set, enabling developers to create a more robust analytical environment for themselves.
Let's walk through an example of a user-defined function - we’ll be counting the total number of combined favourite food, drinks and snacks for a given person’s name by creating a function called count_combined_favourites.
Here’s how to create the count_combined_favourites function:
CREATE OR REPLACE FUNCTION food_preferences.count_combined_favourites(p_name VARCHAR(30))
RETURNS INTEGER
LANGUAGE plpgsql
AS $$
DECLARE
food_count INTEGER;
BEGIN
SELECT COUNT(*) INTO food_count FROM food_preferences.combined_favourites WHERE person_name = p_name;
RETURN food_count;
END;
$$;
The function should be created after running the above, and displayed like so:
Now let’s use the function to obtain Melissa’s favourites:
SELECT food_preferences.count_combined_favourites('Melissa') AS melissa_favourites_count;
Let’s see the results:
| melissa_favourites_count | |
| 1 | 1 |
So Melissa has only listed one record of her favourite food, drink and snack. Great!
→When to use🚦
Functions can be valuable when you want to:
Return single values from data manipulation
Enforce specific business rules into your SQL logic
Reuse the same SQL logic performing complex calculations multiple times in the future
→When to avoid🚫
You probably don’t need to use custom functions if:
simple SQL statements can return the scalar value you require
you do not need to rerun or reuse the same manipulation logic as the overhead of creating the functions may not be justified
Also according to this article, using functions in the WHERE clause can cause performance issues in your SQL scripts, and instead utilizing the LIKE clause instead. I encourage you to have a read and form your own judgement from it.
Triggers🎣
A trigger is a program that automatically executes when a certain event occurs in the database. In other words, a trigger will perform an action when a specific operation happens e.g. add new rows to the HR table each time the employees table is updated.
Triggers are used for monitoring any changes in a database, and once a change is detected, the trigger will run the predefined SQL logic it is provided.
Examples
Now let’s make things more interesting. If you remember from earlier, Melissa only has one favourite food, drink and snack. Melissa has now announced she has more favourites we didn’t consider initially.
To make these triggers work, here’s the plan of action. We will
create log tables to record any new food items that are added as Melissa’s favourites
create the triggers to track the changes in the log tables
insert the new food items on Melissa’s behalf into the source tables
We wouldn’t need to add these new records to the log tables because the triggers will do that for us.
Let’s create the log tables first:
-- 1. Create the food log table
CREATE TABLE IF NOT EXISTS food_preferences.food_log (
log_id SERIAL PRIMARY KEY,
food VARCHAR(30),
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. Create the drink log table
CREATE TABLE IF NOT EXISTS food_preferences.drink_log (
log_id SERIAL PRIMARY KEY,
drink VARCHAR(30),
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 3. Create the snack log table
CREATE TABLE IF NOT EXISTS food_preferences.snack_log (
log_id SERIAL PRIMARY KEY,
snack VARCHAR(30),
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
…then we will create the triggers:
-- 1. Create the trigger for the food insertions
CREATE OR REPLACE FUNCTION food_preferences.log_food_insertion()
RETURNS TRIGGER AS $$
BEGIN
IF NEW.person_name ='Melissa' THEN
INSERT INTO food_preferences.food_log (food) VALUES (NEW.food);
END IF;
RETURN NEW;
END;
$$
LANGUAGE plpgsql;
CREATE TRIGGER trigger_log_food
AFTER INSERT ON food_preferences.favourite_foods
FOR EACH ROW
EXECUTE FUNCTION food_preferences.log_food_insertion();
-- 2. Create the trigger for the drink insertions
CREATE OR REPLACE FUNCTION food_preferences.log_drink_insertion()
RETURNS TRIGGER AS $$
BEGIN
IF NEW.person_name ='Melissa' THEN
INSERT INTO food_preferences.drink_log (drink) VALUES (NEW.drink);
END IF;
RETURN NEW;
END;
$$
LANGUAGE plpgsql;
CREATE TRIGGER trigger_log_drink
AFTER INSERT ON food_preferences.favourite_drinks
FOR EACH ROW
EXECUTE FUNCTION food_preferences.log_drink_insertion();
-- 3. Create the trigger for the snack insertions
CREATE OR REPLACE FUNCTION food_preferences.log_snack_insertion()
RETURNS TRIGGER AS $$
BEGIN
IF NEW.person_name ='Melissa' THEN
INSERT INTO food_preferences.snack_log (snack) VALUES (NEW.snack);
END IF;
RETURN NEW;
END;
$$
LANGUAGE plpgsql;
CREATE TRIGGER trigger_log_snack
AFTER INSERT ON food_preferences.favourite_snacks
FOR EACH ROW
EXECUTE FUNCTION food_preferences.log_snack_insertion();
Now we can add more food items to Melissa’s favourites:
-- 1. Add a new favorite food for Melissa
INSERT INTO food_preferences.favourite_foods (person_name, food) VALUES ('Melissa', 'Sushi');
-- 2. Add a new favorite drink for Melissa
INSERT INTO food_preferences.favourite_drinks (person_name, drink) VALUES ('Melissa', 'Coca Cola');
-- 3. Add a new favorite snack for Melissa
INSERT INTO food_preferences.favourite_snacks (person_name, snack) VALUES ('Melissa', 'Prawn Crackers');
These entries will be appended to their respective log tables because of the triggers.
Let’s create a SQL statement that allows us to view all of the log entries as one table using the UNION ALL command:
SELECT 'food' as item_type, log_id, food AS item, timestamp
FROM food_preferences.food_log
WHERE food = 'Sushi'
UNION ALL
SELECT 'drink' as item_type, log_id, drink AS item, timestamp
FROM food_preferences.drink_log
WHERE drink = 'Coca Cola'
UNION ALL
SELECT 'snack' as item_type, log_id, snack AS item, timestamp
FROM food_preferences.snack_log
WHERE snack = 'Prawn Crackers';
This will return the following:
| item_type | log_id | item | timestamp |
| food | 1 | Sushi | 2023-09-09 00:14:50.36594 |
| drink | 1 | Coca Cola | 2023-09-09 00:14:50.36594 |
| snack | 1 | Prawn Crackers | 2023-09-09 00:14:50.36594 |
When to use🚦
Triggers are useful when you want to:
enforce data validation and integrity checks across your database
validate the updated or inserted data
When to avoid🚫
You should consider avoiding triggers if you:
are running many complex DML tasks like update, insert and delete operations as they can add additional overhead and negatively impact their performances over time
have several nested triggers, as having many complex trigger interactions will make troubleshooting and debugging more difficult
In these scenarios, try considering other alternatives that may be better suited like stored procedures (to handle event monitoring) or constraints (for data validation and integrity checks).