

REST API to MySQL database using Python
Use Python to import data from an API to an RDBMS database


Preface💫
This time, we’ll be sending HTTP requests to a REST API endpoint, format the data into a clean, tabular structure and load them into a MySQL database using Python once again.
Objective🎯
We want to display an up-to-date list of the English Premier League’s top goal scorers in a way that is easy for any football fanatic to understand at a quick glance.
This helps a football enthusiast stay updated on their favourite goal scorers, compare them to other goal scorers and even observe any interesting trends over the course of the season.
Pseudo-code📝
It’s good practice to outline the high-level overview of what we want to do before we get into the technical details of our project.
This gives us a clear idea of the steps needed for each stage of the project and how we want to progress through each of them.
So here’s how we want to approach this:
Define the data we want from the REST API
Send a GET request to the API for the data we want
Transform the data
Load the initial historical data and append more updated data to the MySQL database
Schedule the data pipeline jobs to be executed every 5 mins (using a list of dates provided)
Technologies⚙️
Here are the modules that would support us with this:
Architectural diagram🏛️
Here's a visual representation of this data pipeline:

Data source: REST API🌐
A REST API is an interface that allows a client and a server to exchange information between each other. You can find a quick practical walkthrough with Python on YouTube and TikTok.
We’ll be using a popular football API provided by RapidAPI called API-FOOTBALL. We’ll be referencing the official documentation for the information we lay out here.
Considerations with REST APIs🧐
Here are factors to consider when dealing with REST APIs:
Data availability and scope🔍 - what data does the API offer, and what do we actually need for our project?
Data refresh frequency🕒 - how often is the data updated or refreshed?
Request types📡 - what HTTP requests (GET, POST etc) do we want our queries to process ?
Rate limits🛑- how many API calls can we make in a specific time period?
Authentication🔒 - what credentials do we need for the system to authenticate our requests (API keys or tokens), and how do we securely manage these credentials?
Data format📄 - what is the format of the data returned to us when we make API calls (JSON, XML, other)?
Error handling🚨 - what robust measures do we put in place to handle issues like API limitations, downtime, or unexpected responses?
Data availability and scope🔍
API-FOOTBALL includes a list of endpoints like
Teams
Players
Trophies
Standings
Top Scorers
This project will focus on using the Top Scorers endpoint.
When an API call is made, the results contain 6 keys:
get
parameters
errors
results
paging
response
The data we need is found in the response key. Response is an array of objects with all the detailed information we need about each top goal scorer.
Each item within the response array is structured into two main parts: player and statistics
Player information:
id
name
firstname & lastname
age
birth
nationality
height & weight
injured
photo
Player statistics:
team
league
games
substitutes
shots
goals
passes
tackles
duels
dribbles
fouls
cards
penalty
This is clearly plenty of data to work with, but for this project we’ll simply use the following items:
rank
player
club
total goals
penalty goals
assists
matches
minutes played
age
Data refresh frequency🕒
The endpoint is updated several times a week.
This allows us to align our pipeline’s scheduling with each moment the API is refreshed so that we are operating with the most up-to-date data.
Request types📡
The API only works with GET requests, which is exactly what we need. Any other requests made outside of that will return errors.
A GET request simply means we’re asking the API if we can GET the data we’ve specifically asked for from it. If our authentication details are approved by the server, it will send us the data we’ve requested for.
We’ll use the requests library to send the GET requests to the football API.
Rate limits🛑
Free accounts subscribed to API-FOOTBALL are allocated a maximum of 100 API calls per day, which is convenient for this project.
The docs confirm we can check the rate limits programmatically or through a dashboard. We’ll do it programmatically like this:
def check_rate_limits():
"""
Check the API quota allocated to your account
"""
response = requests.get(url, headers=headers)
response.raise_for_status()
daily_limits = response.headers.get('x-ratelimit-requests-limit')
daily_remaining = response.headers.get('x-ratelimit-requests-remaining')
calls_per_min_allowed = response.headers.get('X-RateLimit-Limit')
calls_per_min_remaining = response.headers.get('X-RateLimit-Remaining')
rate_limits = {
'daily_limit': daily_limits,
'daily_remaining': daily_remaining,
'minute_limit': calls_per_min_allowed,
'minute_remaining': calls_per_min_remaining
}
print(rate_limits)
This will display an output like this:
{'daily_limit': '100', 'daily_remaining': '78', 'minute_limit': None, 'minute_remaining': None}
The docs recommends one call per day is to be made to this endpoint.
If we don’t add mechanisms in place to handle moments where users exceed the API rate limits, this could interrupt and frustrate their experience when analysing the football data.
In a future blog post, I’ll dive into a few strategies we could implement to avoid exceeding the quota allocated for API calls using Python.
Authentication🔒
API-FOOTBALL uses API keys to authenticate each HTTP request made to/from it.
The API key should be saved in a secure environment file. In our case, we have it in a .env file.
We’ll use the python-dotenv module to to load the variables saved in the .env file into our codebase.
Data format📄
Each response is returned in a JSON format.
We’ll use the json module to unpack the appropriate data we need from each array.
Here’s an example of the JSON data in the response object that we would need to unpack:
{
"player": {
"id": 1100,
"name": "E. Haaland",
"firstname": "Erling",
"lastname": "Braut Haaland",
"age": 24,
"birth": {
"date": "2000-07-21",
"place": "Leeds",
"country": "England"
},
"nationality": "Norway",
"height": "194 cm",
"weight": "88 kg",
"injured": false,
"photo": "<https://media.api-sports.io/football/players/1100.png>"
},
"statistics": [
{
"team": {
"id": 50,
"name": "Manchester City",
"logo": "<https://media.api-sports.io/football/teams/50.png>"
},
"league": {
"id": 39,
"name": "Premier League",
"country": "England",
"logo": "<https://media.api-sports.io/football/leagues/39.png>",
"flag": "<https://media.api-sports.io/flags/gb.svg>",
"season": 2023
},
"games": {
"appearences": 21,
"lineups": 20,
"minutes": 1746,
"number": null,
"position": "Attacker",
"rating": "7.404761",
"captain": false
},
"substitutes": {
"in": 1,
"out": 5,
"bench": 1
},
"shots": {
"total": 70,
"on": 42
},
"goals": {
"total": 17,
"conceded": 0,
"assists": 5,
"saves": null
},
"passes": {
"total": 250,
"key": 22,
"accuracy": 9
},
"tackles": {
"total": 4,
"blocks": 1,
"interceptions": 1
},
"duels": {
"total": 120,
"won": 59
},
"dribbles": {
"attempts": 16,
"success": 9,
"past": null
},
"fouls": {
"drawn": 19,
"committed": 13
},
"cards": {
"yellow": 1,
"yellowred": 0,
"red": 0
},
"penalty": {
"won": null,
"commited": null,
"scored": 3,
"missed": 1,
"saved": null
}
}
]
}
Here’s the corresponding code for it:
import requests
import os
import json
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Load API key to make API requests
RAPIDAPI_KEY = os.getenv('RAPIDAPI_KEY')
# Set up the API request details
url = "<https://api-football-v1.p.rapidapi.com/v3/players/topscorers>"
querystring = {"league":"39","season":"2023"}
headers = {
"X-RapidAPI-Key": RAPIDAPI_KEY,
"X-RapidAPI-Host": "api-football-v1.p.rapidapi.com"
}
# Make the API request
response = requests.get(url, headers=headers, params=querystring)
# Check if the request was successful
if response.status_code == 200:
data = response.json()
# Extract information for the first player
first_player_info = data['response'][0]
# Display the first player's information in JSON format
print(json.dumps(first_player_info, indent=4))
else:
print("[ERROR] Failed to retrieve data from the API...")
Error handling🚨
We’ll add error handling mechanisms for
API connection errors
HTTP request issues
timeouts
other potential errors we may not be accounting for (for the sake of brevity)
We’ll use try-except blocks to handle exceptions gracefully.
Code breakdown🧩
1. Set up environment and API request🔏
Before we dive into the code, we set up our environment by storing sensitive information like API keys and database credentials in a .env file.
This keeps our sensitive data away from being exposed in the codebase:
# RAPIDAPI
RAPIDAPI_KEY = "xxxx"
# MySQL
HOST="localhost"
MYSQL_DATABASE="football_stats"
MYSQL_USERNAME="xxxx"
MYSQL_PASSWORD="xxxx"
Then we’ll load our modules and environment variables and set up the headers for our API requests.
This helps authenticate each request we make to the API-FOOTBALL endpoint for Top Scorers.
We are analysing the Premier League’s top goal scorers for the 2023/24 season, as of the time of this writing:
import os
import requests
import pandas as pd
from datetime import datetime
import mysql.connector
from mysql.connector import Error
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Load API key to make API requests
RAPIDAPI_KEY = os.getenv('RAPIDAPI_KEY')
# Set up API request headers to authenticate requests
headers = {
'X-RapidAPI-Key': RAPIDAPI_KEY,
'X-RapidAPI-Host': 'api-football-v1.p.rapidapi.com'
}
# Set up API URL and parameters
url = "<https://api-football-v1.p.rapidapi.com/v3/players/topscorers>"
params = {"league":"39","season":"2023"}
If you haven’t got the modules mentioned, use this pip install command:
pip install python-dotenv requests pandas mysql-connector-python
2. Extract data from the API📥
This step represents the extraction phase of the ETL pipeline (E).
The get_top_scorers() function sends a GET request to the API and handles potential errors that may occur, like HTTP errors or connection timeouts:
def get_top_scorers(url, headers, params):
"""
Fetch the top scorers using the API
"""
try:
response = requests.get(url, headers=headers, params=params)
response.raise_for_status()
return response.json()
except requests.exceptions.HTTPError as http_error_message:
print (f"❌ [HTTP ERROR]: {http_error_message}")
except requests.exceptions.ConnectionError as connection_error_message:
print (f"❌ [CONNECTION ERROR]: {connection_error_message}")
except requests.exceptions.Timeout as timeout_error_message:
print (f"❌ [TIMEOUT ERROR]: {timeout_error_message}")
except requests.exceptions.RequestException as other_error_message:
print (f"❌ [UNKNOWN ERROR]: {other_error_message}")
3. Transform the data🔄
This step represents the transformation phase of the ETL pipeline (T).
Once we’ve extracted the data, we can format it to fit our needs. The process_top_scorers() function parses the JSON response and extracts only the relevant information about each top goal scorer.
You can have a look at the JSON version under the “Data format” section of this article.
We’re also calculating the age of each player from their respective date of births:
def process_top_scorers(data):
"""
Parse the JSON data required for the top scorers
"""
top_scorers = []
for scorer_data in data['response']:
statistics = scorer_data['statistics'][0]
# Set up constants for processing data
player = scorer_data['player']
player_name = player['name']
club_name = statistics['team']['name']
total_goals = int(statistics['goals']['total'])
penalty_goals = int(statistics['penalty']['scored'])
assists = int(statistics['goals']['assists']) if statistics['goals']['assists'] else 0
matches_played = int(statistics['games']['appearences'])
minutes_played = int(statistics['games']['minutes'])
dob = datetime.strptime(player['birth']['date'], '%Y-%m-%d')
age = (datetime.now() - dob).days // 365
# Append data
top_scorers.append({
'player': player_name,
'club': club_name,
'total_goals': total_goals,
'penalty_goals': penalty_goals,
'assists': assists,
'matches': matches_played,
'mins': minutes_played,
'age': age
})
return top_scorers
We’ll pass the output from the process_top_scorers() into the create_dataframe() function to convert the list of dictionaries into a Pandas dataframe:
def create_dataframe(top_scorers):
"""
Convert list of dictionaries into a Pandas dataframe and process it
"""
df = pd.DataFrame(top_scorers)
# Sort dataframe first by 'total_goals' in descending order, then by 'assists' in descending order
df.sort_values(by=['total_goals', 'assists'], ascending=[False, False], inplace=True)
# Reset index after sorting to reflect new order
df.reset_index(drop=True, inplace=True)
# Recalculate ranks based on the sorted order
df['position'] = df['total_goals'].rank(method='dense', ascending=False).astype(int)
# Specify the columns to include in the final dataframe in the desired order
df = df[['position', 'player', 'club', 'total_goals', 'penalty_goals', 'assists', 'matches', 'mins', 'age']]
return df
4. Load data into MySQL database💾
This step represents the load phase of the ETL pipeline (L).
Now it’s time to load the data into our database in MySQL! We’ll load the credentials we need into this session:
HOST = os.getenv('HOST')
MYSQL_DATABASE = os.getenv('MYSQL_DATABASE')
MYSQL_USERNAME = os.getenv('MYSQL_USERNAME')
MYSQL_PASSWORD = os.getenv('MYSQL_PASSWORD')
We use the following SQL code to create a database called football_stats for this demo in MySQL Workbench - (you can download MySQL Workbench by clicking this link here):
CREATE DATABASE IF NOT EXISTS football_stats;
SHOW DATABASES

…then we’ll connect to our MySQL database using the database credentials we’ve just pulled from the .env file:
def create_db_connection(host_name, user_name, user_password, db_name):
"""
Establish a connection to the MySQL database
"""
db_connection = None
try:
db_connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful ✅")
except Error as e:
print(f"❌ [DATABASE CONNECTION ERROR]: '{e}'")
return db_connection
Once we’ve established a connection to our database, we can create a SQL table in the football_stats database called top_scorers if it doesn’t exist:
def create_table(db_connection):
"""
Create a table if it does not exist in the MySQL database
"""
CREATE_TABLE_SQL_QUERY = """
CREATE TABLE IF NOT EXISTS top_scorers (
`position` INT,
`player` VARCHAR(255),
`club` VARCHAR(255),
`total_goals` INT,
`penalty_goals` INT,
`assists` INT,
`matches` INT,
`mins` INT,
`age` INT,
PRIMARY KEY (`player`, `club`)
);
"""
try:
cursor = db_connection.cursor()
cursor.execute(CREATE_TABLE_SQL_QUERY)
db_connection.commit()
print("Table created successfully ✅")
except Error as e:
print(f"❌ [CREATING TABLE ERROR]: '{e}'")
Then we’ll finally insert the data into the SQL table:
def insert_into_table(db_connection, df):
"""
Insert or update the top scorers data in the database from the dataframe
"""
cursor = db_connection.cursor()
INSERT_DATA_SQL_QUERY = """
INSERT INTO top_scorers (`position`, `player`, `club`, `total_goals`, `penalty_goals`, `assists`, `matches`, `mins`, `age`)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
`total_goals` = VALUES(`total_goals`),
`penalty_goals` = VALUES(`penalty_goals`),
`assists` = VALUES(`assists`),
`matches` = VALUES(`matches`),
`mins` = VALUES(`mins`),
`age` = VALUES(`age`)
"""
# Create a list of tuples from the dataframe values
data_values_as_tuples = [tuple(x) for x in df.to_numpy()]
# Execute the query
cursor.executemany(INSERT_DATA_SQL_QUERY, data_values_as_tuples)
db_connection.commit()
print("Data inserted or updated successfully ✅")
5. Execute the ETL pipeline⏯️
The run_data_pipeline() function is the single point of entry we use to run all the data processing steps in a logical order:
def run_data_pipeline():
"""
Execute the ETL pipeline
"""
check_rate_limits()
data = get_top_scorers(url, headers, params)
if data and 'response' in data and data['response']:
top_scorers = process_top_scorers(data)
df = create_dataframe(top_scorers)
print(df.to_string(index=False))
else:
print("No data available or an error occurred ❌")
db_connection = create_db_connection(HOST, MYSQL_USERNAME, MYSQL_PASSWORD, MYSQL_DATABASE)
# If connection is successful, proceed with creating table and inserting data
if db_connection is not None:
create_table(db_connection)
df = create_dataframe(top_scorers)
insert_into_table(db_connection, df)
if __name__ == "__main__":
run_data_pipeline()
Results🏆
Let’s enter MySQL Workbench to view the results using the following command:
SELECT
`top_scorers`.`position`,
`top_scorers`.`player`,
`top_scorers`.`club`,
`top_scorers`.`total_goals`,
`top_scorers`.`penalty_goals`,
`top_scorers`.`assists`,
`top_scorers`.`matches`,
`top_scorers`.`mins`,
`top_scorers`.`age`
FROM
`football_stats`.`top_scorers`
ORDER BY
`top_scorers`.`total_goals` DESC,
`top_scorers`.`assists`DESC;

So we can now analyse our data however we see fit!
Players with the highest goal-to-minute ratio
Let’s find out who the most efficient goal scorers are on this list:
SELECT
`player`,
`club`,
`total_goals`,
`mins`,
ROUND((`total_goals` / NULLIF(`mins`, 0)), 4) AS goals_per_minute
FROM
`football_stats`.`top_scorers`
WHERE
`mins` > 0
ORDER BY
goals_per_minute DESC
LIMIT 10;
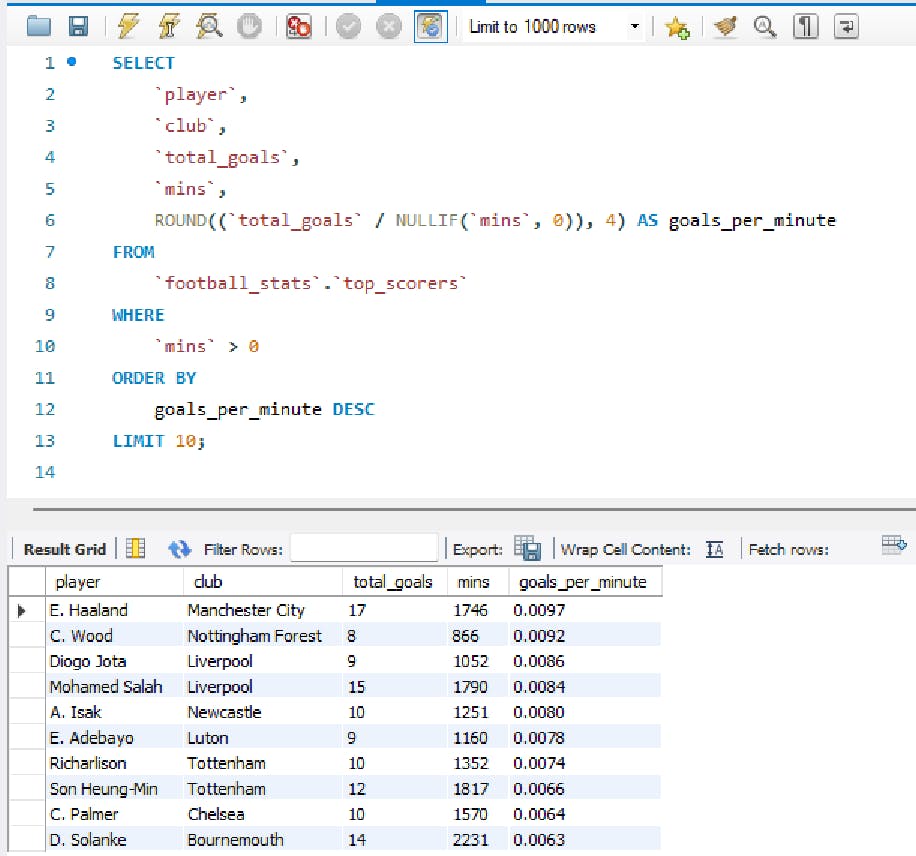
This is useful for finding out which players require the least amount of time to scorer the most amount of goals.
Players with the most assists
Now let’s explore which goal scorers are also helping other teammates score goals too:
SELECT
`player`,
`club`,
`assists`,
`matches`,
ROUND((`assists` / NULLIF(`matches`, 0)), 2) AS assists_per_match
FROM
`football_stats`.`top_scorers`
WHERE
`matches` > 0
ORDER BY
assists_per_match DESC,
`matches` ASC
LIMIT 10;
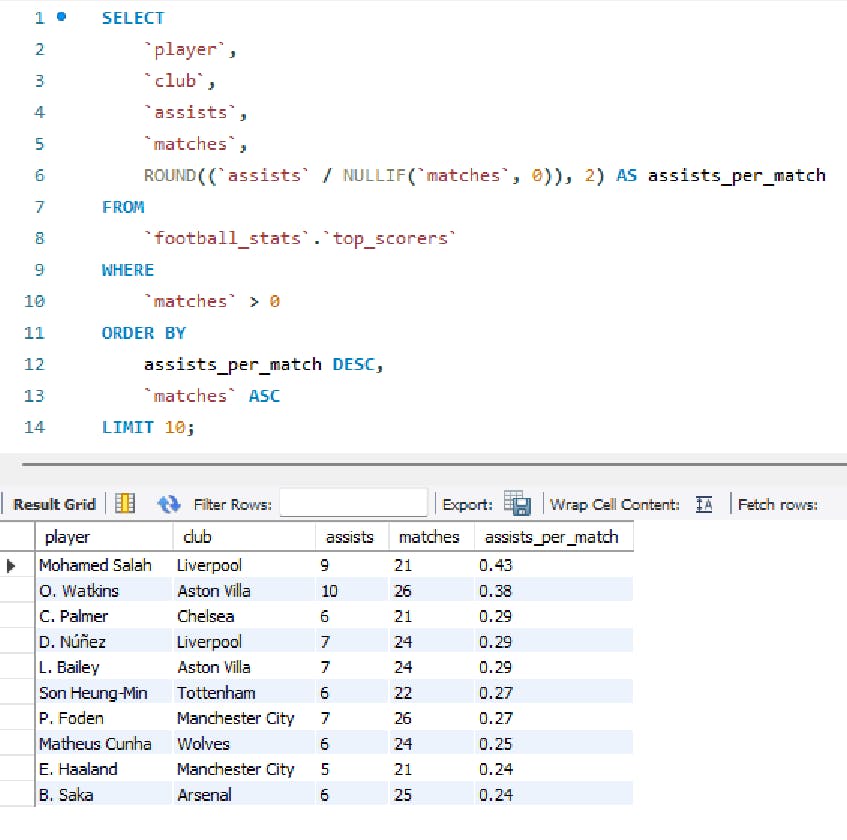
This provides us with insight into players that not just score goals for their teams, but create opportunities for other players to score too.
Age distribution among top goal scorers
SELECT
`age`,
COUNT(*) AS number_of_players
FROM
`football_stats`.`top_scorers`
GROUP BY
`age`
ORDER BY
`age`;
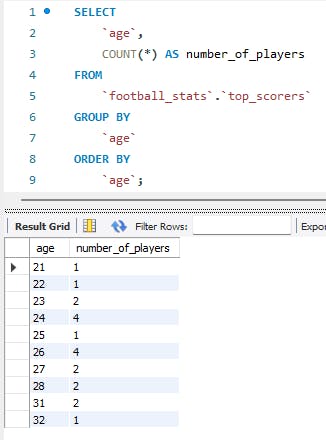
This could be useful in understanding the age of peak performance among goal scorers in the Premier League. This would be even more useful if compare to different top scorers over a certain period of time (in years).
Key takeaway🔑
It is possible to load data from a REST API into a RDBMS database combining Python and SQL together instead of using one over the other ✅
I’d encourage you to expand on the code examples used in this article and tailor them to scenarios appropriate for your initiatives and projects.
Check out the code 👾
You can find the code examples used in this article on GitHub here.
Let’s connect! 💬
🎥 If you prefer seeing these projects in video format, subscribe/follow these channels:
🌐 You can also connect with me through these handles:
Feel free to share your feedback, questions and comments if you have any!