Preface
One of the most popular file formats for flat files in data engineering is the JSON (JavaScript Object Notation) format. A typical JSON file is made up of key-value pairs, where the key is the name of a value or object and the value is the object's value in a string, number, boolean, list, or object format (among others).
Why JSON?
1. Communicating with external servers
JSON objects are used as a means of communicating with a server via API endpoints. When an app needs to retrieve or send messages to the server, it sends an HTTP request to the server. The server processes the request and sends back a response in JSON format.
In many cases, the server's response is parsed by the client (i.e. the app) before it's displayed to the user, and then the client uses the parsed data to update its UI in a user-friendly format. In some scenarios, such as when designing and building custom applications or solutions, developers may choose to work directly with unparsed JSON data from the server.
2. Storing data in databases
More databases are offering support for storing data in JSON format. One example is MongoDB, a NoSQL database that saves data in BSON format (Binary JSON). With this approach you aren't required to design the schema structure of your data before saving it.
This flexibility is becoming more attractive to companies looking to store and retrieve complex data structures with ease. With Spark, this can be achieved at massive scales.
3. Generating configuraiton files
JSON files are also commonly used for configuring systems and applications. They store metadata such as application structure, settings and environment variables that control the behaviour of the system in different scenarios.
Because JSON files are lightweight, different programming languages can easily parse, read and access the metadata they contain to perform another set of actions.
Demo
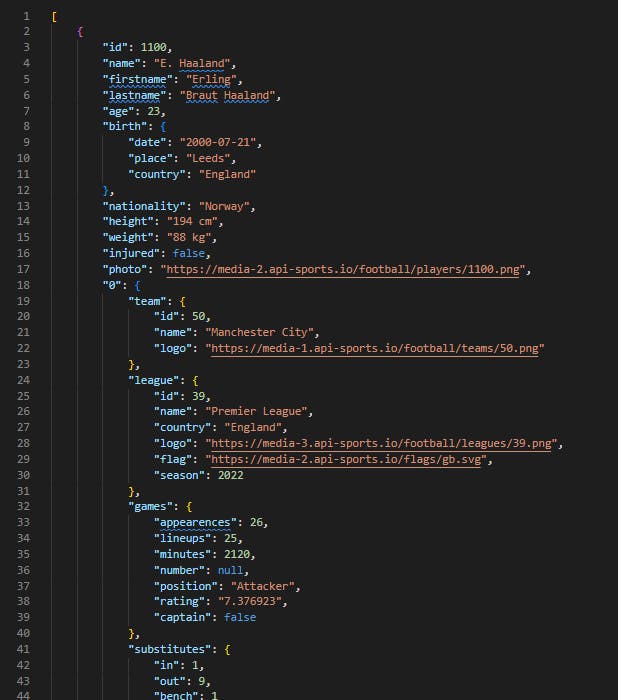
This is a quick tutorial on how to process (or flatten) JSON files using Spark. For demonstration purposes, I will be using a JSON file that contains data on the top scorers of the Premier League (2022/23 season) as of 16/03/2023. I generated this from a REST API call to an online football API:
Steps
1. Read JSON file into Spark data frame
You can use either of the following:
A.
df_1 = spark.read.option("multiline", True).json.(json_file_path)
B.
df_1 = spark.read.format("json").option ("multiline", True).load(json_file_path)
Set multiline to True if the JSON data contains nested fields
2. Select nested fields from the Struct field
from pyspark.sql.functions import col
df_2 = (df_1.select(
col("0.*"))
)
If the main nested field is struct type, select all the columns within the field combining the dot notation and wildcard syntax as above. If it’s an array or map type, explode it using the explode function to break the array into individual rows.
3. Add row IDs to both data frames
from pyspark.sql.functions import monotonically_increasing_id
df_1 = df_1.withColumn("row_id", monotonically_increasing_id())
df_2 = df_2.withColumn("row_id", monotonically_increasing_id())
This code uses monotonically_increasing_id() function to create a row_id column that assigns a unique integer to each row in increments
4. Join data frames by row ID
merged_df = df_1.join(df_2, on="row_id", how="outer").drop("row_id")
5. Split JSON data to separate fields
# Drop "0" struct field
merged_df = merged_df.drop("0")
# Split JSON data to separate fields
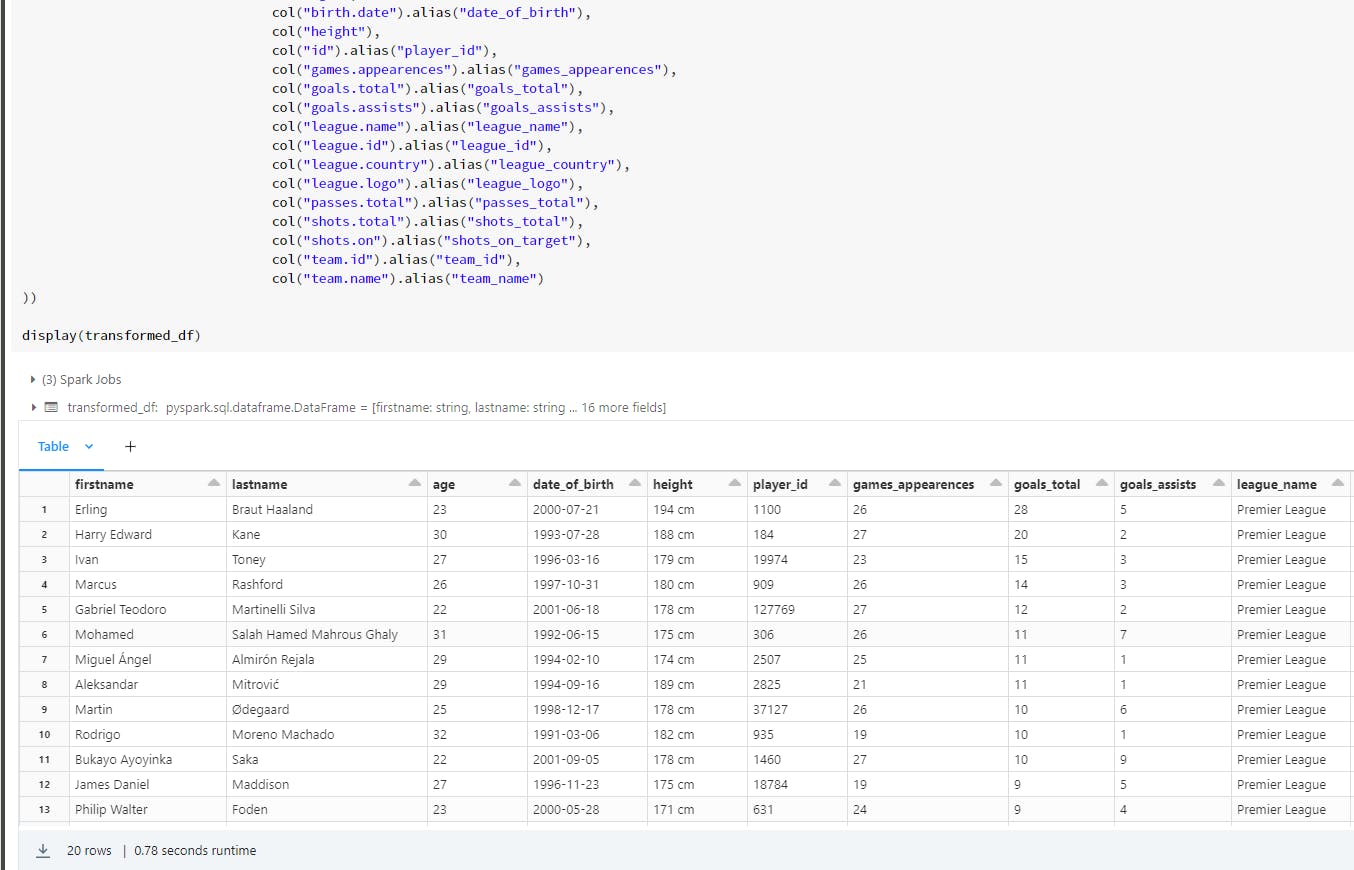
transformed_df = (merged_df.select(
col("firstname"),
col("lastname"),
col("age"),
col("birth.date").alias("date_of_birth"),
col("height"),
col("id").alias("player_id"),
col("games.appearences").alias("games_appearences"),
col("goals.total").alias("goals_total"),
col("goals.assists").alias("goals_assists"),
col("league.name").alias("league_name"),
col("league.id").alias("league_id"),
col("league.logo").alias("league_logo"),
col("passes.total").alias("passes_total"),
col("shots.total").alias("shots_total"),
col("shots.on").alias("shots_on_target"),
col("team.id").alias("team_id"),
col("team.name").alias("team_name")
))
Here’s the output: