


Table of contents
- Preface 🎬
- Solutions💡
- What AI tools can we develop?🤖🛠️
- Chatbot retrieval augmentation flow
- Applying custom AI tools to data engineering use cases➕
- Verdict?🤨
- Conclusion🏁
Preface 🎬
In part 1, we explored the common challenges faced by data engineers to provide context into how AI tools can help solve these problems.
In this article, we now explore the solutions AI tools can provide to solving these problems.
Solutions💡
The year 2023 has been an eventful year in the world of AI. We’ve witness incredible breakthroughs with the introduction of large language models (LLMs) demonstrating cutting-edge capabilities which can be channelled into real world use cases, with OpenAI setting pace to these breakthroughs through ChatGPT and GPT-3 & GPT-4 models.

Photo by Mariia Shalabaieva on Unsplash
What AI tools can we develop?🤖🛠️
AI agents — these are assistants completely powered by their respective LLM capabilities to perform different tasks
AI bots — these are tools that follow a sequence of steps to perform a task automatically
AI chatbots — these are conversational agents that hold a human-like dialogue with humans and manage retrieval-augmented tasks

Photo by Mohamed Nohassi on Unsplash
So how do we create our own version of ChatGPT with our own external data we can secure from unauthorized users and entities (including OpenAI themselves) while leveraging the power of these LLMs?
Example of an AI chatbot architecture🧠🔨
Here is an example of an architecture we can start with for building an AI chatbot that can hold conversations about any information on our databases, documents and websites:
Data sources 🖨️- where the data originates from
Data processor🔄 — the pipeline that cleans the data and splits it into smaller chunks for the AI model to consume easily
Embeddings engine🧮- the model that converts data into an array of numbers
Indexing engine 🗃️- the object that organises the embeddings into indexes
Knowledge base 📚- where the relevant answers are stored and extracted from the vector indexes
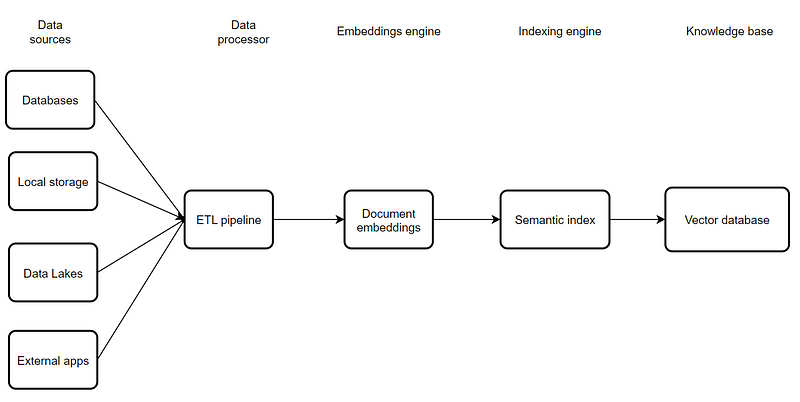
Image created by author
With this architecture, you can build AI chatbots that serve as
AI Data Analysts
Customer support agents
Research assistants
Study assistants
Business/executive advisors
Office assistants
Legal assistants
Chatbot retrieval augmentation flow
For both technical and non-technical users, they can
insert their external data into the chatbot
ask the chatbot questions about the data uploaded
respond to the answers given by the chatbot
During a conversation with the user, everything the chatbot knows is found within its knowledge base. A knowledge base is the user’s external data fed into the vector database. Each AI chatbot powered with an LLM uses a process known as retrieval augmentation.
Retrieval augmentation is the process of searching the knowledge base for the answers most appropriate to the user’s queries. This ensures the chatbot can only answer questions using the information found in the knowledge base.
Here’s how the chatbot retrieval augmentation flow works behind the scene:
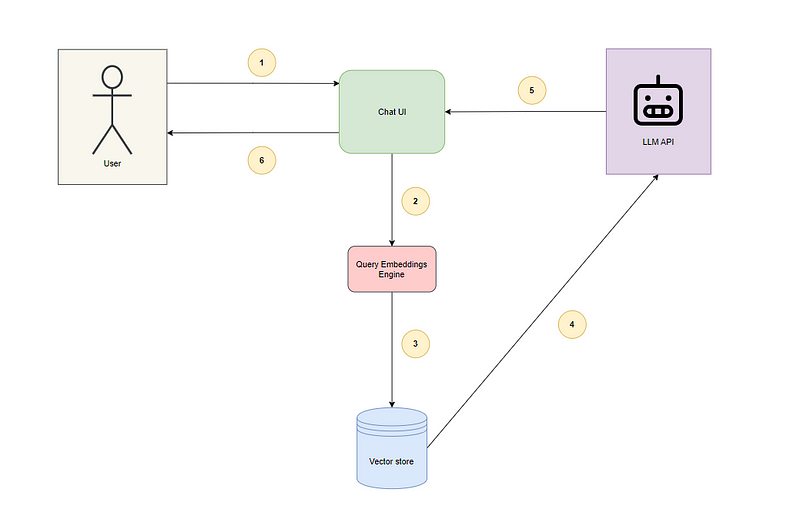
Image created by author
The user sends their query (question or message) to the chat assistant via the UI
The query is converted into embeddings
The query embeddings are used to perform similarity/semantic search to retrieve the answers most relevant to the user’s query
The results from the vector store are ranked and sent to the LLM
The LLM generates a personalized response with the results
The chat assistant displays the LLM’s response to the user
Using this chatbot retrieval flow, two types of chatbots can be created:
No-code solution👨💻❌
Code solution👨💻✅
Note: In this article, I will only touch on the high-level overview of boilerplate tools that can be assembled to create a custom AI chatbot. I will delve into a deeper technical dive in the later series.
1. No-code solution👨💻❌
Here’s a breakdown of the components involved in the no-code approach:
BotPress — for developing the chatbot’s conversation flow and providing the user interface (UI) for conversating with the chatbot
StackAI — the proprietary tool for hosting the AI workflows to make conversating with the LLM model possible
Flowise + LangChain + Render — the open-source tool for hosting the AI workflows to make conversating with the LLM model possible
Pinecone — the proprietary tool for storing embeddings as indexed vectors
OpenAI API — for interacting with the GPT models for embeddings and conversational retrieval
2. Code solution 👨💻✅
These are examples of some of the tools you can explore for the coding approach:
Python — the programming language for processing the data for the AI chatbot to consume and respond on
Anaconda — to manage the Python modules in a virtual environment
Streamlit — to host the chatbot UI in a local environment
Faiss — an open-source vector database for storing embeddings as indexed vectors
OpenAI API — for interacting with the GPT models for embeddings and conversational retrieval
GPT Function Calling — for passing the JSON outputs returned from the GPT model’s API through our Python functions
Langflow — for creating AI applications and chatbots programmatically
Applying custom AI tools to data engineering use cases➕
The chatbot’s main selling point is the data the user uploads to the knowledge base. From a data engineering standpoint, there are several data sources we can connect to the chatbot to provide contextual information to the user, like:
APIs
CRMs
Websites
FTP portals
Data platforms
Databases (relational + non-relational)
Data Lakes (S3, Azure Blob, GCP, others)
Local machines (laptops, mobile devices, hard drives)
Here are some examples that could spark some ideas on how you can create custom use cases with your custom AI chatbots that could meet your requirements:
Data Quality📊
A custom AI chatbot can assist with some of the data quality issues we may encounter in our pipelines. We can
create a data quality testing framework
perform spot checks after running data quality tests
ask it to perform its validation checks (on top of the ones we may already have) or create its own recommended testing suite based on what it’s observed from ours
request it to review and provide recommendations for optimizing our existing testing suite based on its observations
Here are examples of conversation flows you could have around this:
Example 1
User: "Check the tables in PostgresSQL database for any duplicates, missing records or NULL values"
Chat Assistant: "I have found 4 duplicate records in the sales_2023 table, 18 missing records in the purchases_2023 table but no NULL values in any table. Would you like me to send these results to anyone?"
User: "Yes, send them to Tim Cook. His email is timcook@nottheappleguy.com. You can send it after lunch."
Chat Assistant: "No problem! I will send this around 1pm to Tim Cook via his email 'timcook@nottheappleguy.com' in a PDF format."
Example 2
User: "Verify if the employees_2023 table schema matches the schema specification made in the approved data contracts."
Chat Assistant: "There are no mismatches in the employees_2023 table schema, however I did notice a mismatch in the inventory_migration_2019 table for the 'stock_id' and 'description' fields."
User: "I didn't notice that...what should I do to rectify this?"
Chat Assistant: "Change the data types for both fields from 'LongType' and 'IntegerType' to 'StringType'. This should correct the field mismatch identified."
Data Governance🏛️🔒
An AI chatbot can assist with some of the issues faced with data governance in a data team. It can:
create a data governance framework based on the current data team’s context
manage and audit all access permissions across all platforms
send alerts about aged access permissions and security groups
Here are examples of conversation flows you could have around this:
Example 1
User: "Perform an audit on the roles allocated to each team based on the role-based access control framework I provided you and flag any mismatches you notice."
Chat Assistant: "The audit has been completed. There are three anomalies identified. This has now been forwarded to the data governance team to review. "
Example 2
User: "Grant Penelope Smith from the Marketing team access to the production Azure Blob container "
Chat Assistant: "I see that you are not included in the appropriate security group for me to perform this - do you have the right approval from Management before I go ahead with this request?? "
User: "Yes, I have an email approval from Melissa to action this "
Chat Assistant: "No problem - send it to me and I'll also let Melissa know if she's happy to advance with this. Once she approves, I'm happy to grant Penelope access immediately."
Example 3
User: "Who are all the users that have access to the sales data for 2022?"
Chat Assistant: "Here are all the users who have access to the sales data: 1. John Doe, 2. Penelope Smith, 3. Michael Jordon "
User: "When was John Doe granted access to this, and who approved it and why?"
Chat Assistant: "John does was granted access to this on 13 August 2018. This was approved by Axel Washington (Head of Sales) so that John can help with building the data pipeline for sales reporting when members in the team take annual leave."
User: "What would happen if John wasn't provided this access?"
Chat Assistant: "This would result in John creating his own sales data pipelines on his local machine, creating data silos that would impact the quality of the sales reported to the management team. This would decrease the overall data quality."
Data Orchestration🎛️
With the AI chatbot, we can
check the progress or status of orchestration jobs without needing to enter its main UI
retrieve information on DAGs, tasks and their dependencies
troubleshoot job failures and get to the main issue with errors and request recommendations on how to fix them
The knowledge base for data orchestration would include metadata on the DAGs, their task instances, job information, operator information, task dependencies, scheduling times & frequencies, which can be found in the orchestration tool’s metadata database. For example, with Airflow, this metadata could be stored in an SQLAlchemy or PostgreSQL database, which can be plugged into the data processor stage. You could also download or scrape Airflow’s documentation and insert it into the data processor stage too to be ingested into the vector database.
Here are examples of conversation flows you could have around this:
Example 1
User: "What does the DAG for the AWS inventory data look like, and its task dependencies"
Chat Assistant: "Here is how the DAG for AWS inventory data is structured in the source code: aws_glue_job_operator_1, aws_glue_job_operator_2, aws_glue_job_operator_3 >> python_operator "
Chat Assistant: "This means there are 3 AWS Glue jobs that are executed in parallel, which will trigger a Python job once completed"
Example 2
User: "Highlight the bottlenecks in our current task flows in Airflow"
Chat Assistant: "There are 5 tasks that appear to be running one after the other for the'Transformation' stage - try making them 5 parallel tasks to save time and resources for this stage."
User: "Any other suggestions?"
Chat Assistant: "I would also recommend adding a task that partitions the large tables in the 'Transformation' stage to speed up performance. I estimate it should speed up performance by about 2 mins."
Data Observability👁️🖥️
AI chatbots can help with data observability issues, by:
alerting the right users with the right information based on their roles
reporting on key metrics about a data pipeline’s data health, uptime, incidents the responses provided
capturing issues in data pipelines early in test and development environments
Creating a knowledge base with this would involve connecting to the API of the data observability service of your choice. Tools like Datadog, Monte Carlo and Databand all have APIs that allow developers to connect their custom AI chatbots to, which allow the LLMs to provide personalized messages to users on the data workflows of their choice.
Here are examples of conversation flows you could have around this:
Example 1
User: "Provide a summary of the system performance metrics every Tuesday at 8am"
Chat Assistant: "Scheduled successfully. You will receive a system performance report every Tuesday at 8am via email."
User: "Also send it to Jerry in the BI team"
Chat Assistant: "I will also send this to Jerry Crawford in the BI team to his email 'jerrycrawford@randombusiness.com' every Tuesday at 8am too."
Example 2
User: "Summarize the data lineage for the marketing data migration pipeline in Databricks"
Chat Assistant: "There are 3 nodes in this pipeline representing 3 data processing stages- the bronze, silver and gold. The bronze node ingests data from an Azure Blob container, the silver curates the data in 5 transformation steps, and the gold aggregates the data and writes outputs to an S3 bucket."
User: "Great! Now write this in a way that is easy for the CEO to understand and email this to him."
Chat Assistant: "I've written a draft of this email and sent it to you - have a look in your inbox and let me know if I should send it. You can confirm this within this chat."
User: "I've just read it - you can send it"
Chat Assistant: "Done - email sent successfully to Brian Machintosh (CEO). "
Data Transformation⚙️
Data engineers can use AI chatbots to support efforts in data transformation, they can:
write a transformation strategy that includes
the clear micro data cleaning steps required to shape the data into the desired format and structure
the tools, modules and dependencies to action this and how they can work together
provide recommendations to optimize the performance and resource usage of data pipelines
debug data pipelines quicker than humans
capture bugs in data pipelines within test simulations before they are rolled out to production
extract, transform and load data by themselves and present it in a user-friendly format
For the knowledge base, you can add data platform design specifications, acceptance criteria, data glossaries + dictionaries, entity relationship diagrams etc. Companies use platforms like Confluence and Jira to store many of these data assets which can be exported or converted into PDF, text, JSON, CSV etc. You can interact with these platforms via their APIs which can enable the chatbot to send HTTP requests to pull the relevant information to answer user queries.
Here are examples of conversation flows you could have around this:
Example 1
User: "I created a custom CDC process for a Spark streaming query in Databricks - how can I optimize its performance?"
Chat Assistant: "1. Try creating an upsert function 2. Make sure you utilize Delta Lakes, 3. Add the upsert function to the foreachBatch() operation in your silver streaming query"
Example 2
User: "Extract and clean data about public sentiment on processed food in 2023"
Chat Assistant: "Beginning extract and cleaning process regarding the general public's sentiment on processed food in 2023..."
Chat Assistant: "Done - data saved to S3 bucket"
User: "Merge this data with the 2022 version and send to the team's main inbox"
Chat Assistant: "All done - successfully merged with 2022 data and sent to the team's main inbox at 'researchteam@foodcompany.com'. "
Data Modelling📈
Data teams can use custom AI chatbots to assist with data modelling tasks, like:
create data dictionaries for all tables in a database
generating entity relationship diagrams
mapping and describing relationships between entities across all tables using the data dictionaries
simulating different data models to preview the best one for performance and cost
simply find out what your database schema looks like (field names, data types, constraints etc)
creating the data model that includes the
a. cardinality (one-to-one, one-to-many etc)
b. granularity (e.g. should date columns stop at the year, month, day or go as deep as the hour, minute and seconds?)
c. schema model (star or snowflake)
d. slowly changing dimensions (type 0, 1, 2…)
The knowledge base for this would include data contracts that specify the data schema expectations and delivery routes, client requirements specifications, etc. Data sources can include data warehouses, document management platforms, etc.
Here are examples of conversation flows you could have around this:
Example 1
User: "Create a data dictionary for each table within the revenue_FY23 database"
Chat Assistant: "Now creating a data dictionary split into fields, data types, descriptions and last modified"
Example 2
User: "Create a data model for the data warehouse initiative discussed in this morning's meeting"
Chat Assistant: "Sure, now creating a data model using the specifications found on the data team's main Confluence workspace"
User: "Also create an ERD for it too"
Chat Assistant: "Now generating an ERD for the data model created..."
Example 3
User: "Update the existing data model for the 'customers' table with the new customer data"
Chat Assistant: "Sure, would you also like me to update the ERD to reflect the changes?"
User: "Yeah sure, and let the team know of the changes you've made too please"
Chat Assistant: "Definitely, now actioning as requested..."
Data Storage☁️💾
In the context of data storage, AI chatbots can:
find the location of files and folders easily
track and monitor files in specific folders, blob containers or buckets and their retention periods
design folder structures to organise file storage and make file retrieval easier
report the storage cost of each file and folder stored in specific locations
The knowledge base for this would include real-time metadata from the cloud platforms and local machine operating systems (OS). Information like this would require programming — languages like Python should be able to extract this metadata and insert it into the vector database.
Here are examples of conversation flows you could have around this:
Example 1
User: "Open the last Excel spreadsheet I updated"
Chat Assistant: "Searching and opening the last Excel spreadsheet you updated..."
Chat Assistant: " 'dev/sales_and_expenses_FY21.xlsx' now opened..."
Example 2
User: "Where is the file that contains the Python code for transforming electronics data? I forgot where it's saved..."
Chat Assistant: "Searching for Python script for transforming electronics data..."
Chat Assistant: "I have found 2 Python scripts that transform electronics data - here are their file locations: 1. (first_file_location), 2. (second_file_location)"
Data Testing🧪
We can use custom AI chatbots to create a robust testing suite for checking the quality of data processed by the pipelines and submit them to the relevant stakeholders in a personalized format for each of them.
Here are examples of conversation flows you could have around this:
Example 1
User: "Study the data design specifications and come up with an ideal test suite that validates the data quality at each stage"
Chat Assistant: "Now reading the design specifications..."
Chat Assistant: "Now desiging a testing suite..."
Chat Assistant: "I have written a draft of what the tests would look like for the data pipelines, how to implement them and what each test is validating."
Example 2
User: "I've just completed the unit tests for the Spark streaming queries and it all seems fine. Send the results to the stakeholders "
Chat Assistant: "I've checked the test results and noticed there are a few errors in the results - have you had a look at them?"
User: "Really? Where??"
Chat Assistant: "The errors appear in test 3, 5 and 14 - they return missing records, NULL values present and duplicate values. Let me know if you would like recommendations on how to fix them."
Data Infrastructure🏢
The custom AI chatbots would be useful for
creating a new or future data estate
optimizing an existing data estate
auditing a data estate to review the monthly or annual cost of running it
provide recommendations around the ideal tool stack for specific requirements
provide reminders on maintenance and patching infrastructure components
providing a data migration strategy for moving data from one data platform or infrastructure to another
The knowledge base for the data infrastructure part would include design specifications, client requirements gathered from conversating with the stakeholders, and data contracts among other documents that include details on the current and future data infrastructure.
Here are examples of conversation flows you could have around this:
Example 1
User: "Design an optimized version of the current data infrastructure that maximizes the components of our current setup "
Chat Assistant: "Done! Successfully created an optimized data infrastructure and sent it via email"
Example 2
User: "Create a data migration strategy based on the data platform's design patterns located on the main Confluence design workspace"
Chat Assistant: "Now reading design specifications and creating a data migration strategy..."
Chat Assistant: "Data migration strategy now completed - you can find this in the Data Team's main Azure Blob container"
Data Acquisition 📡
Some data pipelines are only needed for pulling data from certain sources. AI chatbots can assist data engineers with the tasks involved with this, like
writing acquisition patterns ingesting data from multiple sources
managing existing streaming acquisition pipelines
Here are examples of conversation flows you could have around this:
Example 1
User: "Design acquisition pipelines that pull online data on customer feedback around our CX"
Chat Assistant: "Now creating data acquisition pipelines via Spark streaming jobs and Selenium..."
Chat Assistant: "Completed successfully - would you like me to email this to you?"
User: "Yes please :) "
Chat Assistant: "Done - let me know if you need anything else!"
Verdict?🤨
Yes, these chatbots can be beneficial to engineering teams, but it’s important to note that they do not perform data engineering tasks on behalf of the engineers, they simply accelerate the time it takes to get from problem to solution, so consider these chatbots as accelerators, not replacers — at least not anytime soon 😉.
LLMs when utilized correctly, can create substantial advantages throughout an organisation through data engineering. However, if misused or not correctly implemented, they could cause significant problems down the line that may not be immediately obvious.
Conclusion🏁
The key takeaway is this: there are areas where AI and data engineering can meet to accelerate value across any organisation, but don’t fall victim to the sales pitch of any online guru or emerging AI expert that claims you must buy AI today or witness your company fall into smithereens. Your decisions must be driven by the pain points you experience in your daily operations — if you believe AI tools are the best approach to tackling them, proceed. If not, explore alternative tools that are better positioned to address your needs with the resources at your disposal.
In part 3, I’ll walk you through a real example of an AI chatbot that could be used in a real world scenario. One thing we can’t deny is that we are entering a world where anyone will be able to create AI systems to meet their needs at every level, but there’s also so much information flying around it’s often difficult to take the first step to make this a reality.
But feel free to reach out via my handles and I’ll be happy to point you in the right direction where I can: LinkedIn| Email | Twitter | Tiktok